局部敏感哈希(LSH)
Goal
Finding Similar Items
- 在高维空间上找到那些相近的元素。比如,在做微博文本挖掘的时候,会发现很多微博是高度相似的,因为大量的微博都是转发其他人的微博,并且没有添加评论,导致很多数据是重复或者高度相似的。这给我们进行数据处理带来很大的困扰,我们得想办法把找出这些相似的微博,再对其进行去重处理。

Steps

Shingling
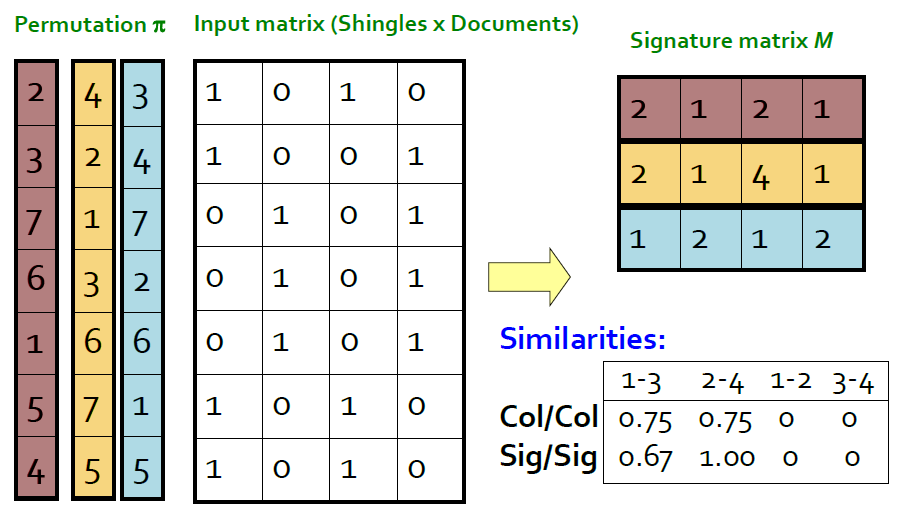
Min-Hashing
Convert large sets to short signatures, while preserving similarity.

LSH
General idea: Use a function f(x,y) that tells whether x and y is a candidate pair: a pair of elements whose similarity must be evaluated
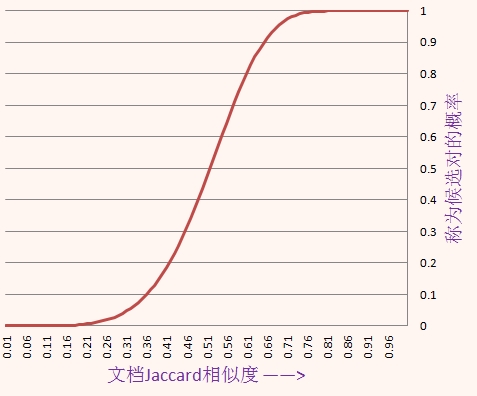
我们对签名矩阵按行进行分组,将矩阵分成b组,每组由r行组成.
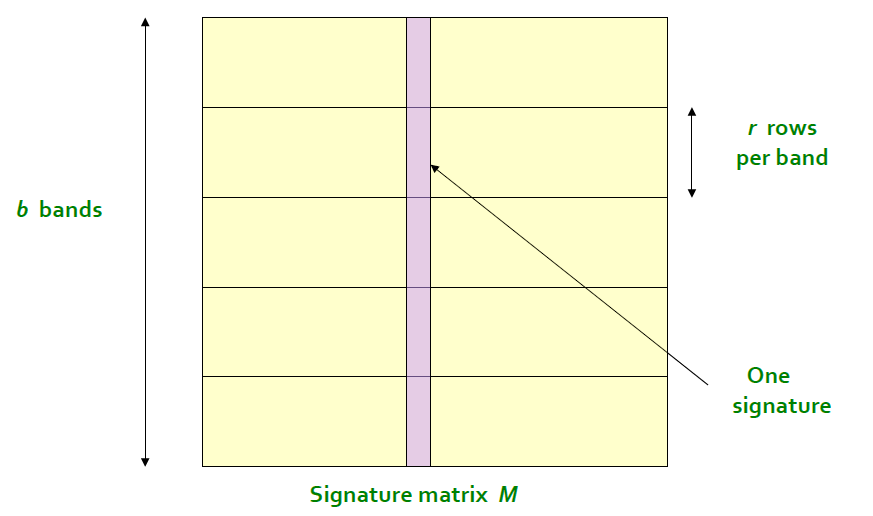
分组之后,我们对最小签名向量的每一组进行hash,各个组设置不同的桶空间。只要两列有一组的最小签名部分相同,那么这两列就会hash到同一个桶而成为候选相似项。签名的分析我们知道,对于某个具体的行,两个签名相同的概率p =两列的相似度= sim(S1,S2),然后:
在某个组中所有行的两个签名值都相等概率是p^r;
在某个组中至少有一对签名不相等的概率是1−p^r;
在每一组中至少有一对签名不相等的概率是(1−p^r)^b;
至少有一个组的所有对的签名相等的概率是1−(1−p^r)^b;
于是两列成为候选相似对的概率是1−(1−p^r)^b,它采样值以及曲线如下: